使用PySpark集成R英格兰vs伊朗让球Studio Workbench和Jupyter#
概述#
本文档描述了使用RStudio Workbench的步骤,英格兰vs伊朗让球前身为RStudi英格兰vs伊朗让球o Server Pro1,使用Jupyter notebook和PySpark连接到Spark集群。
在本例中,Apache Hadoop YARN被用作Spark集群上的资源管理器,您将使用PySpark创建交互式Python会话。

先决条件#
- 英格兰vs伊朗让球在一台服务器上配置了Jupyter笔记本的RStudio Workbench
- Hadoop集群配置Spark和YARN
- 从RStudio Wor英格兰vs伊朗让球kbench到Spark集群的访问
请注意
RStu英格兰vs伊朗让球dio Workbench服务器必须能够访问Spark集群以及YARN和HDFS的底层配置文件。这通常需要您使用Hadoop管理工具(如Cloudera Manager或Ap英格兰vs伊朗让球ache Ambari)在Spark集群的边缘节点(即网关节点)上安装RStudio Workbench。您也可以通过将配置文件从Spark集群复制到RStudio Workbench服务器来实现这一点。英格兰vs伊朗让球
添加RS英格兰vs伊朗让球tudio Workbench作为边缘/网关节点#
对于管理员
介绍单节点作为Spark客户端加入Hadoop集群的过程。该步骤通常由Hadoop管理员执行。在本例中,我们使用Cloudera Manager,但这些步骤也可以适用于其他Spark集群,如Amazon EMR。
这个过程可能会根据Cloudera Distribution Hadoop (CDH)的不同版本、身份验证和其他变量而有所不同。指的是Cloudera经理文档为更多的信息。
步骤1:向Hadoop集群添加一个新主机#
因为您已经有一个安装了RStudio Workbench的服务器,所以第一英格兰vs伊朗让球步是将RStudio Workbench节点添加到现有的Cloudera CDH集群中。
从Cloudera经理Dashboard,选择下拉菜单,单击添加主机.
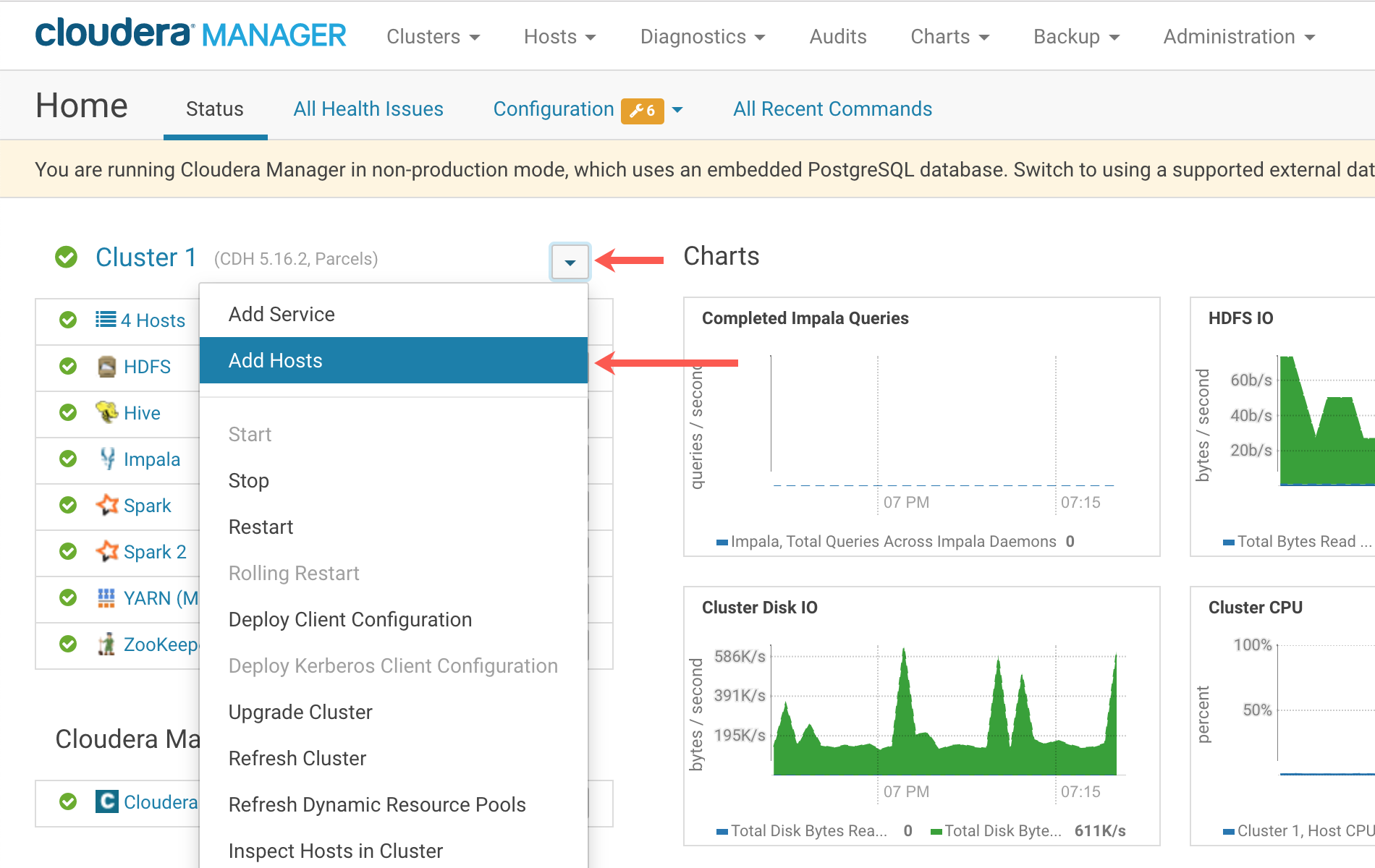

接下来,单击经典的向导在第一页。
步骤2:指定RStudio Workbench节点的主机名英格兰vs伊朗让球#
继续安装,直到它要求指定要添加的节点的主机名。添加RStudio Workbench节点的主机名。英格兰vs伊朗让球
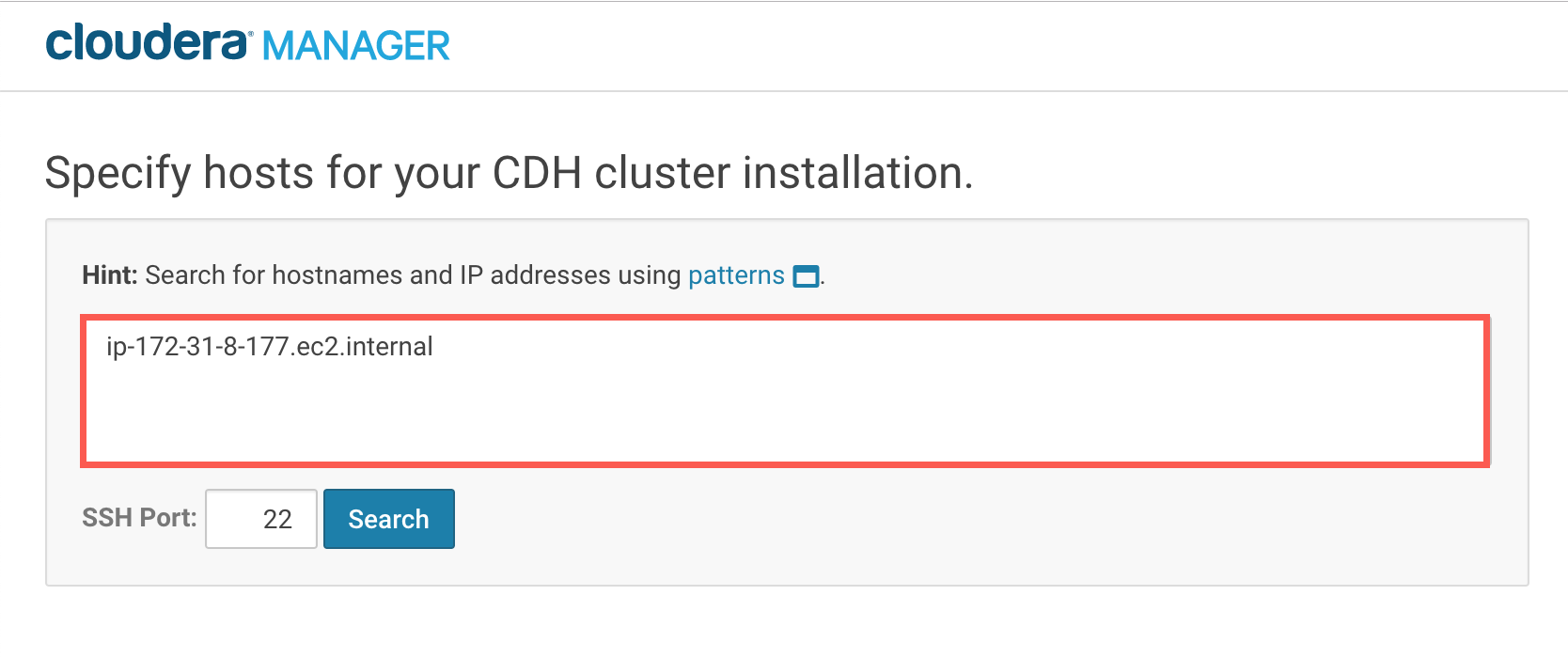
这个主机名应该可以从Cloudera CDH集群访问,当您单击时,Cloudera Manager将验证这一点搜索.
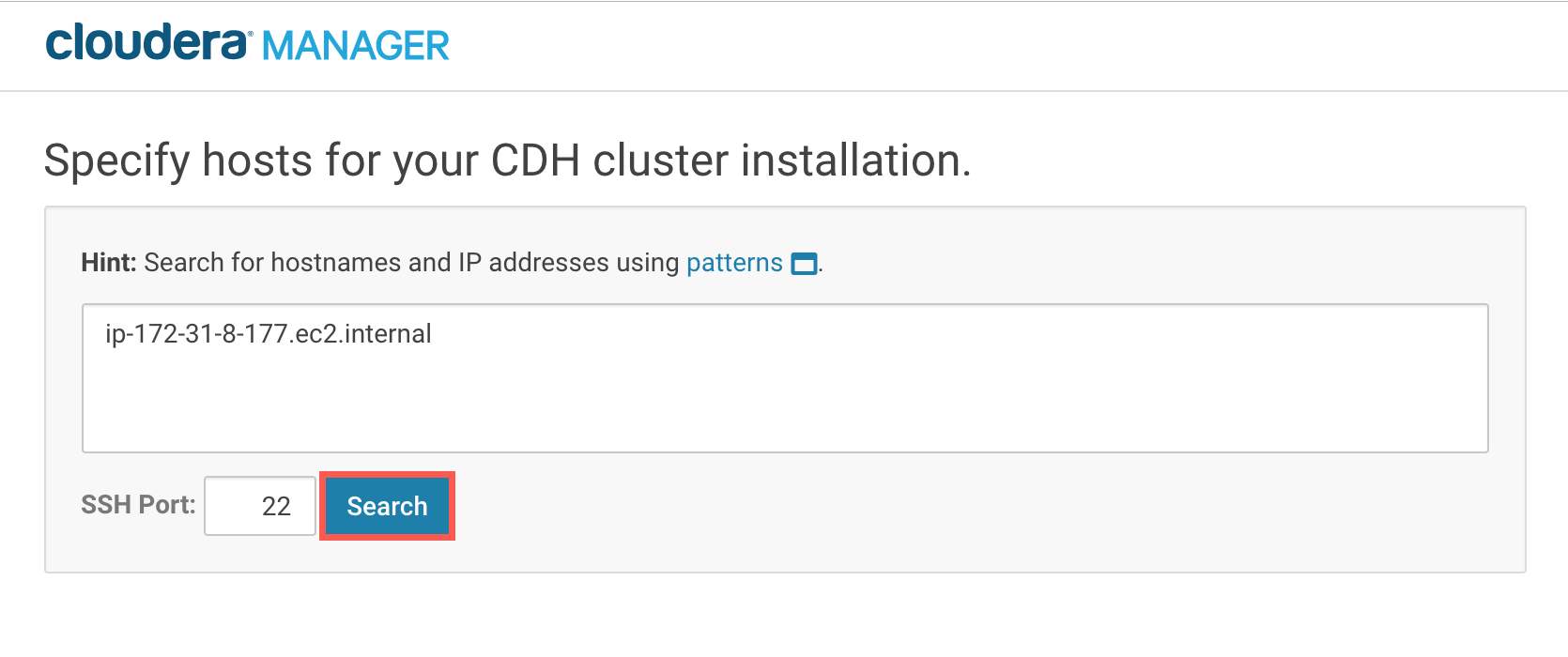
当一切都验证后,点击继续.
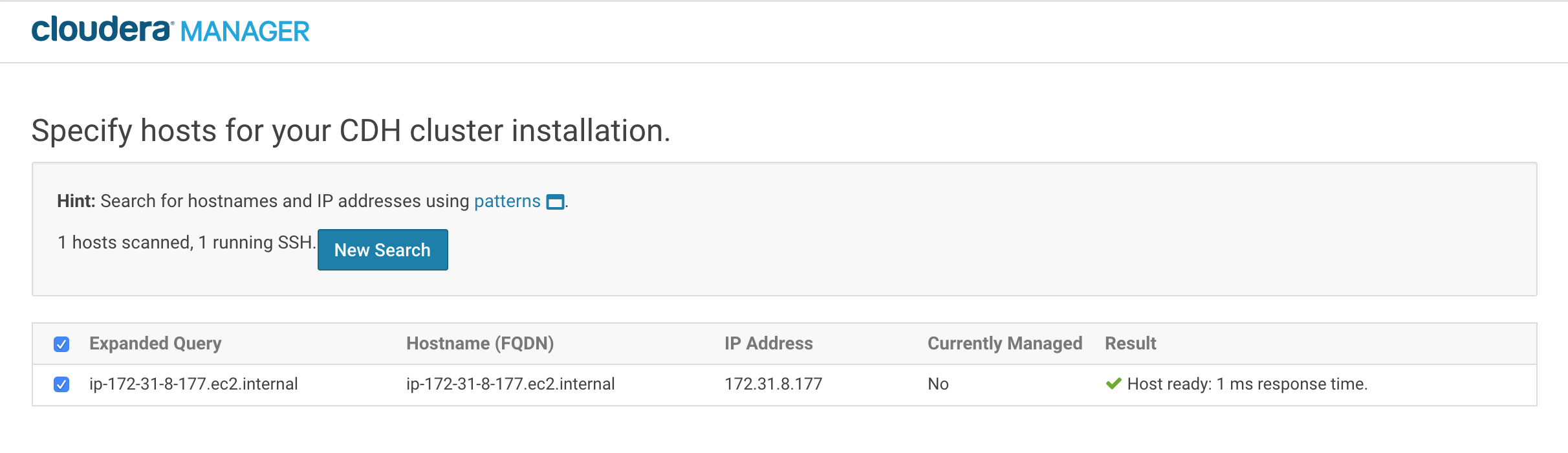



步骤3:为RStudio Workbench节点指定凭据英格兰vs伊朗让球#
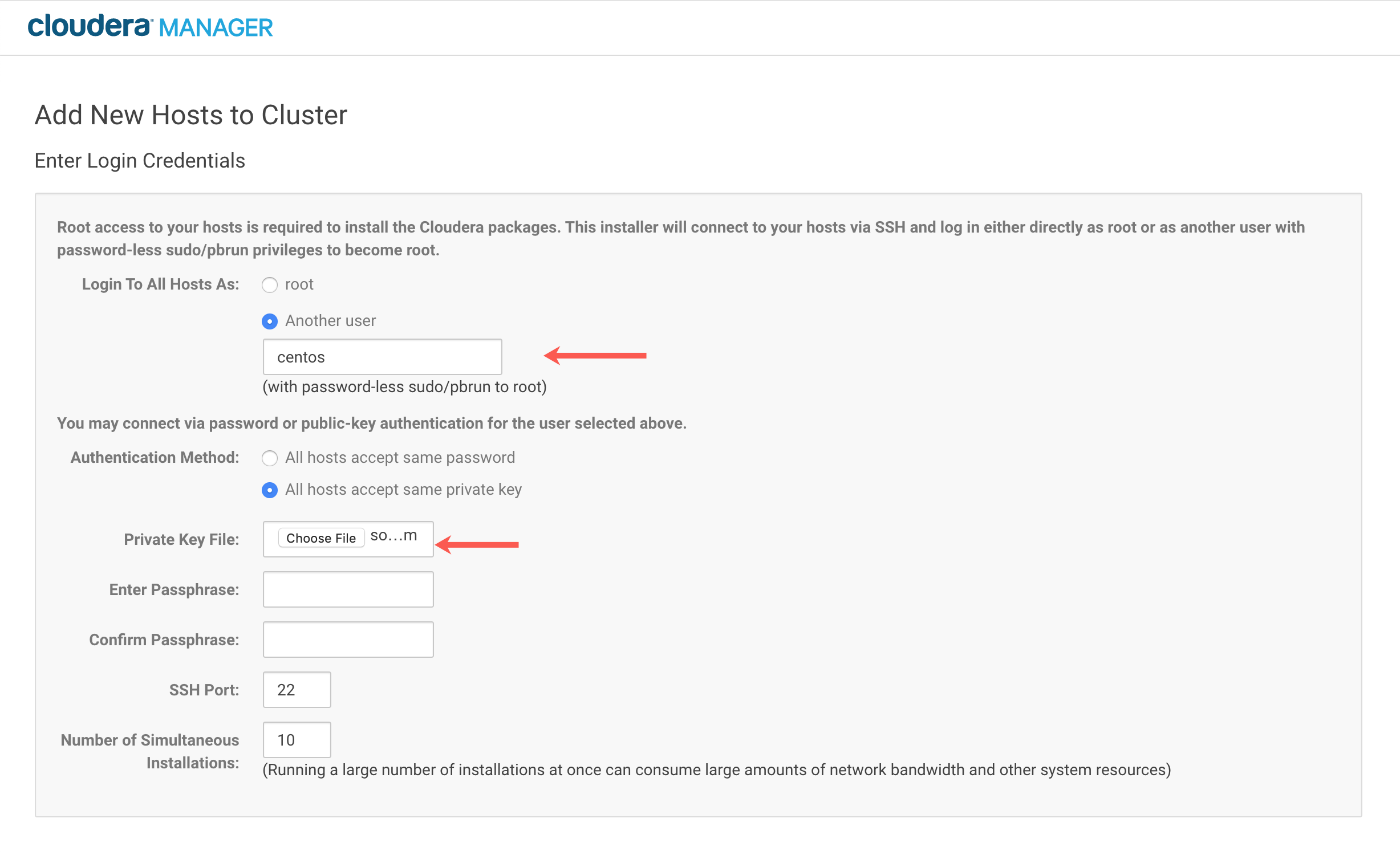
- 继续安装向导,直到它要求RStudio Workbench节点的登录凭证。英格兰vs伊朗让球
在本例中,我们使用带有用户名的Amazon EC2实例centos以及通过私钥进行身份验证。根据您访问RStudio Workbench节点的方式,您可能正在使用不同的身份验证/凭证机制。英格兰vs伊朗让球
步骤4:等待Cloudera Manager代理和包安装完成#
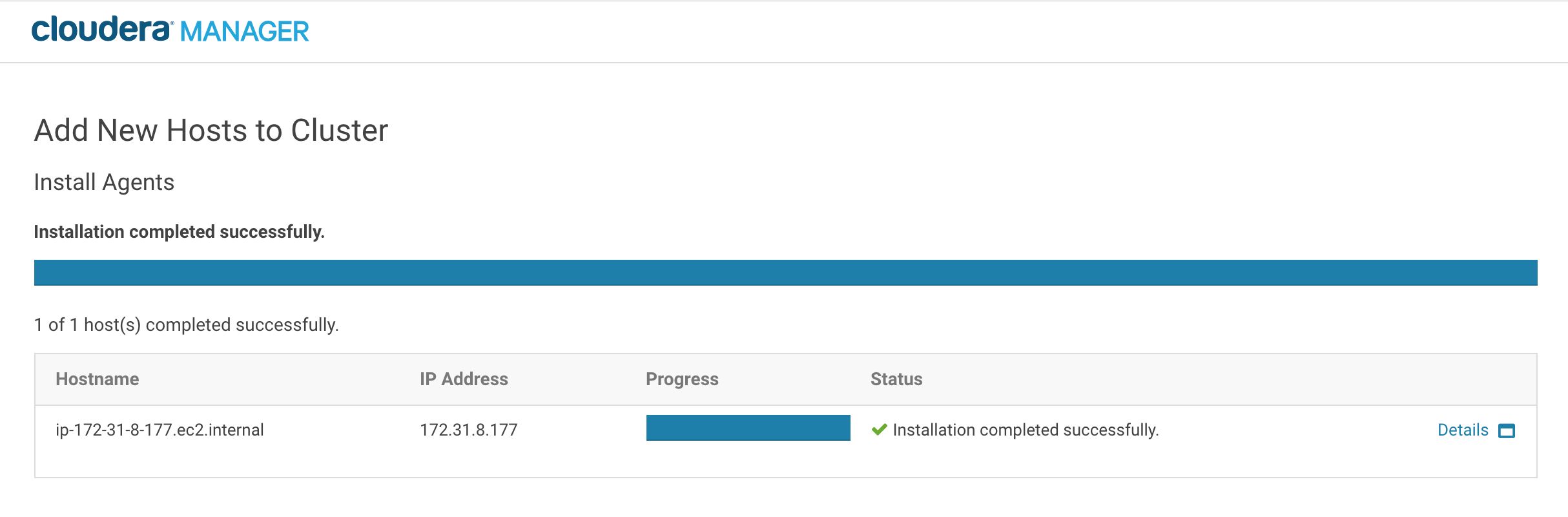
如果主机名和凭据正确,Cloudera Manager将在RStudio Workbench节点上安装Cloudera Manager代理。英格兰vs伊朗让球
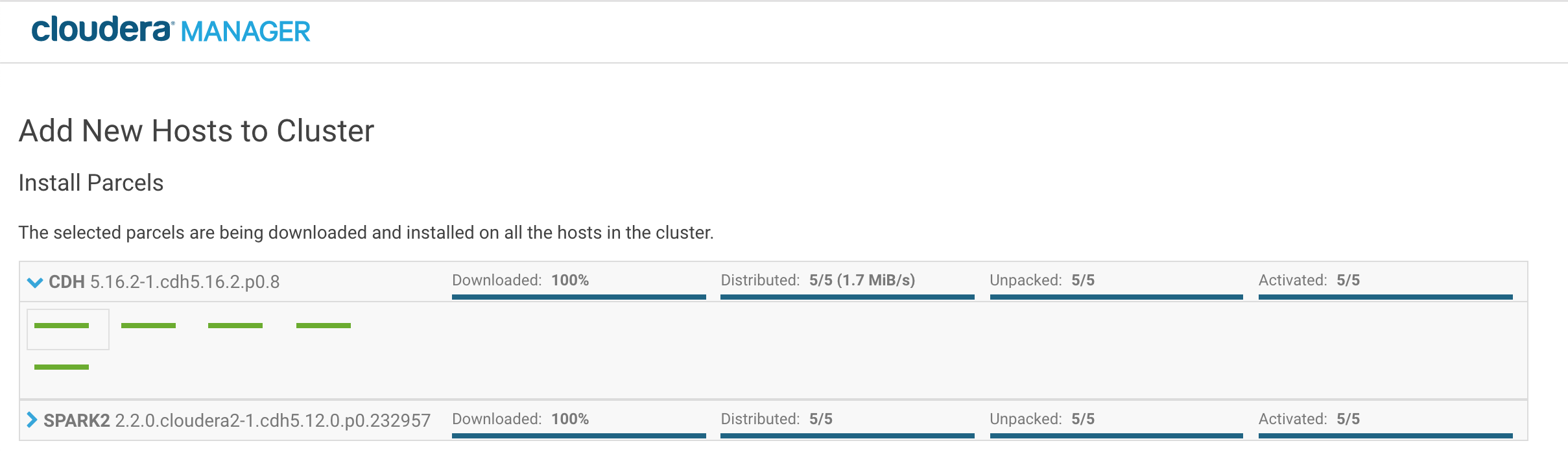
然后将在节点上安装Cloudera CDH包(这可能需要几分钟)。
步骤5:验证添加了带有RStudio Workbench的新主机英格兰vs伊朗让球#
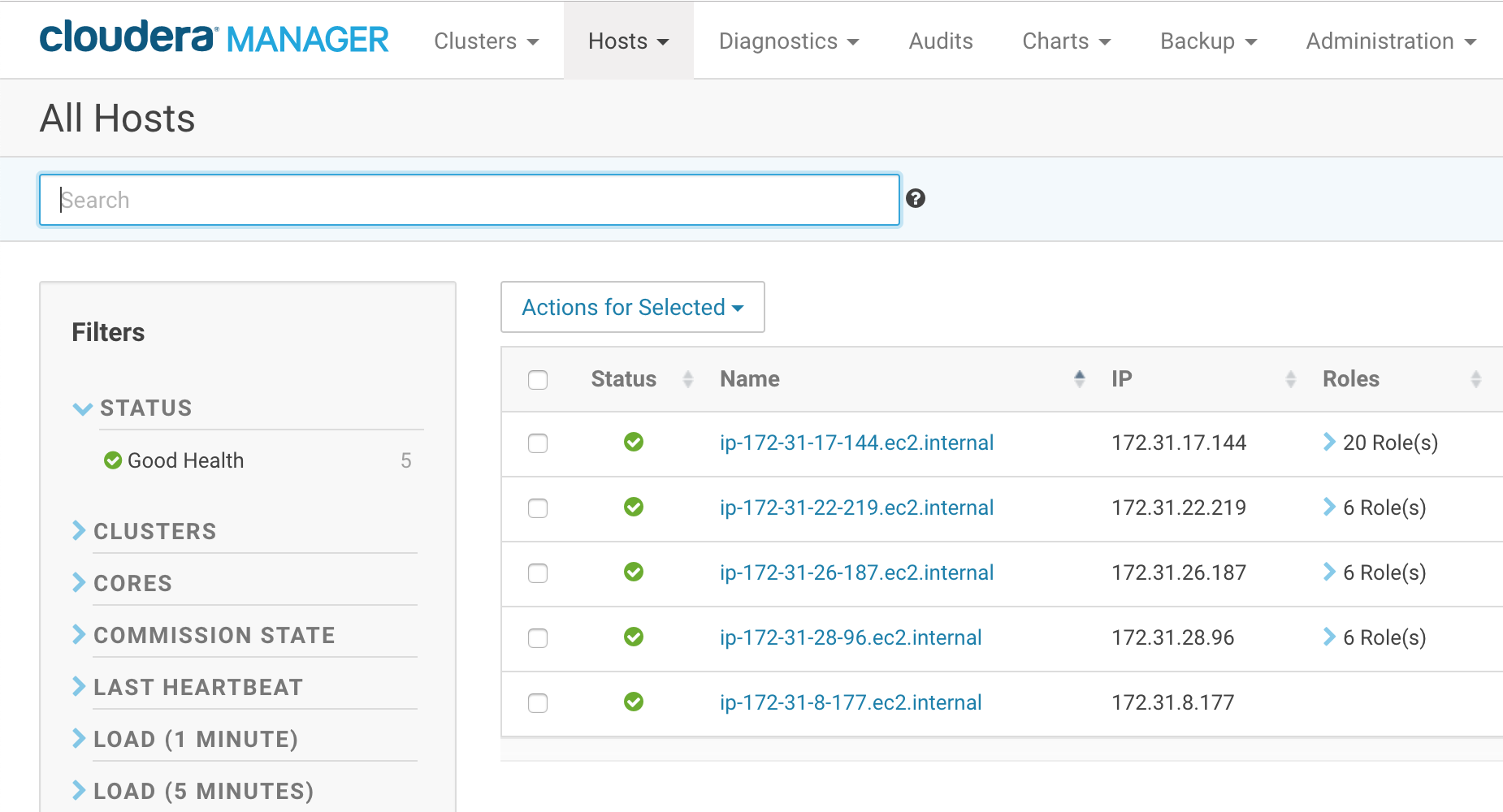
- 继续安装,Cloudera Manager将检查主机。如果一切安装正确,那么RStudio Workbench节点将加入Hadoop集群。英格兰vs伊朗让球
- 验证RStudio Workbe英格兰vs伊朗让球nch节点是否出现在主机列表中。最初,这个节点没有任何角色,但是您将在接下来的步骤中添加必要的角色。
步骤6:向RStudio Workbench节点添英格兰vs伊朗让球加角色#
您现在可以向RStudio Workbench节点添加角色英格兰vs伊朗让球。需要添加的角色如下所示:
- HDFS网关
- 纱网关
- 蜂巢网关
- 火花网关
- Spark2网关(如果您的Cloudera CDH集群安装了Spark2)
方法的示例如下火花网关角色到Cloudera 英格兰vs伊朗让球Manager中的RStudio Workbench节点。然后,您可以为所有必要的角色重复此过程。
进入Cloudera Manager首页,选择待添加服务的页签,单击添加角色实例.

下网关选项,点击选择主机.
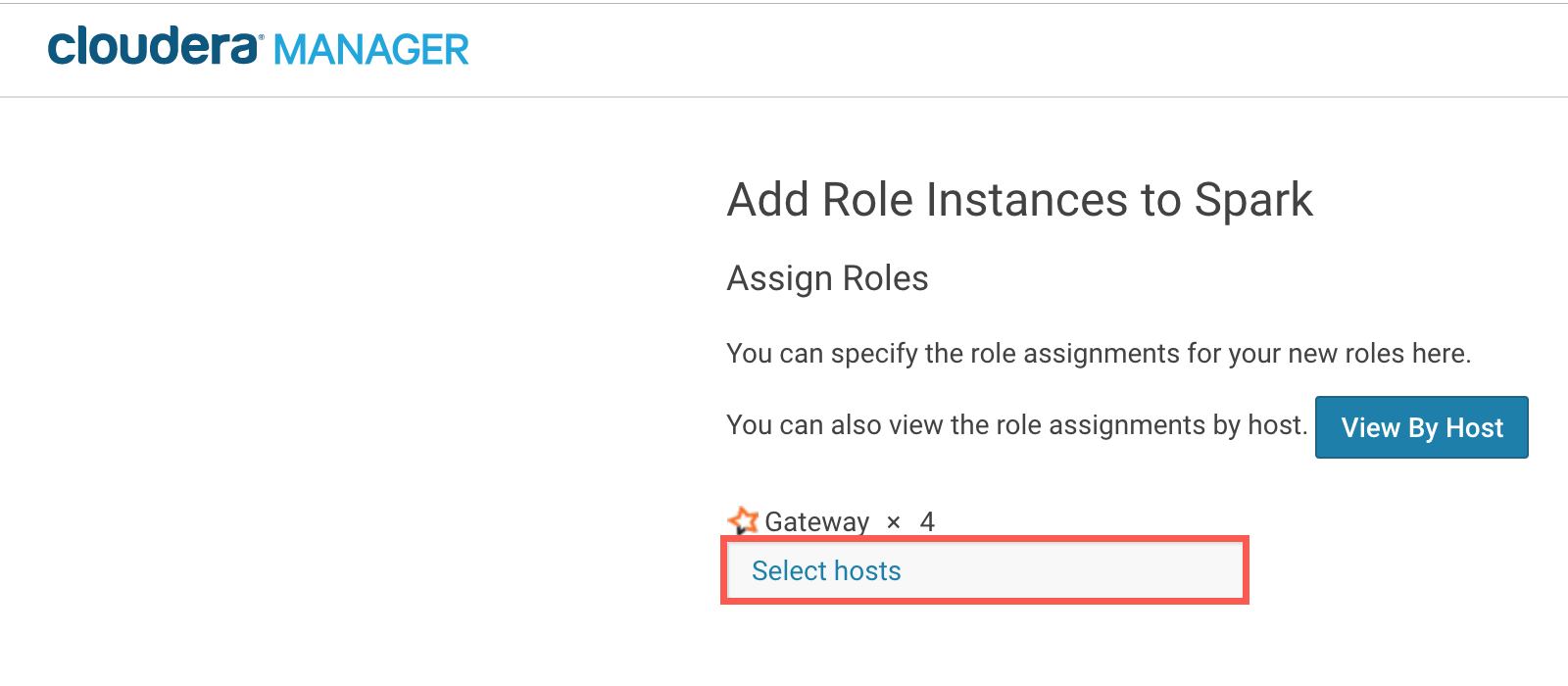
从节点列表中选择RSt英格兰vs伊朗让球udio Workbench节点。




您现在应该看到RStudio Workbenc英格兰vs伊朗让球h节点被选中网关选择。
一定要验证RStudio Workbench节点的主机名。英格兰vs伊朗让球
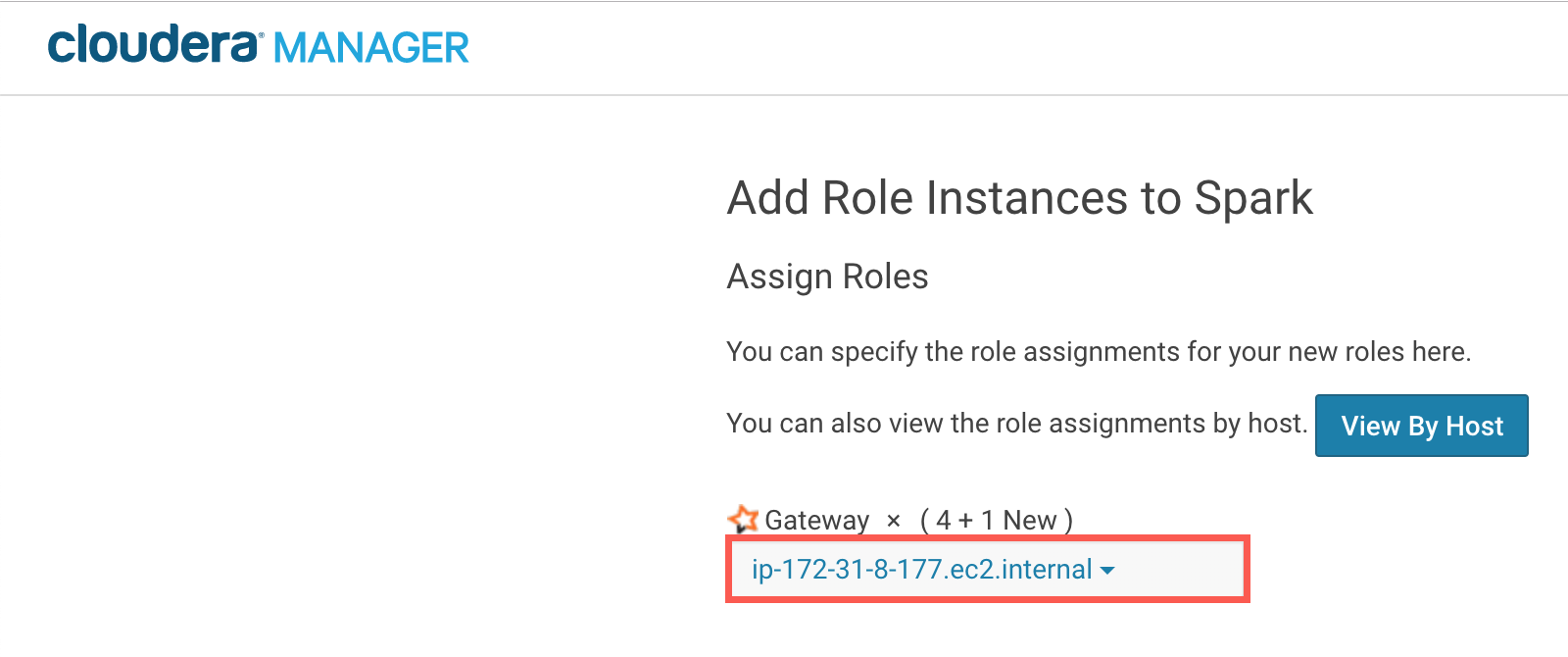
执行向导中的步骤,然后单击重新部署客户机配置部署按钮。
然后,您可以重复此过程以添加上面列出的所有必要的角色。


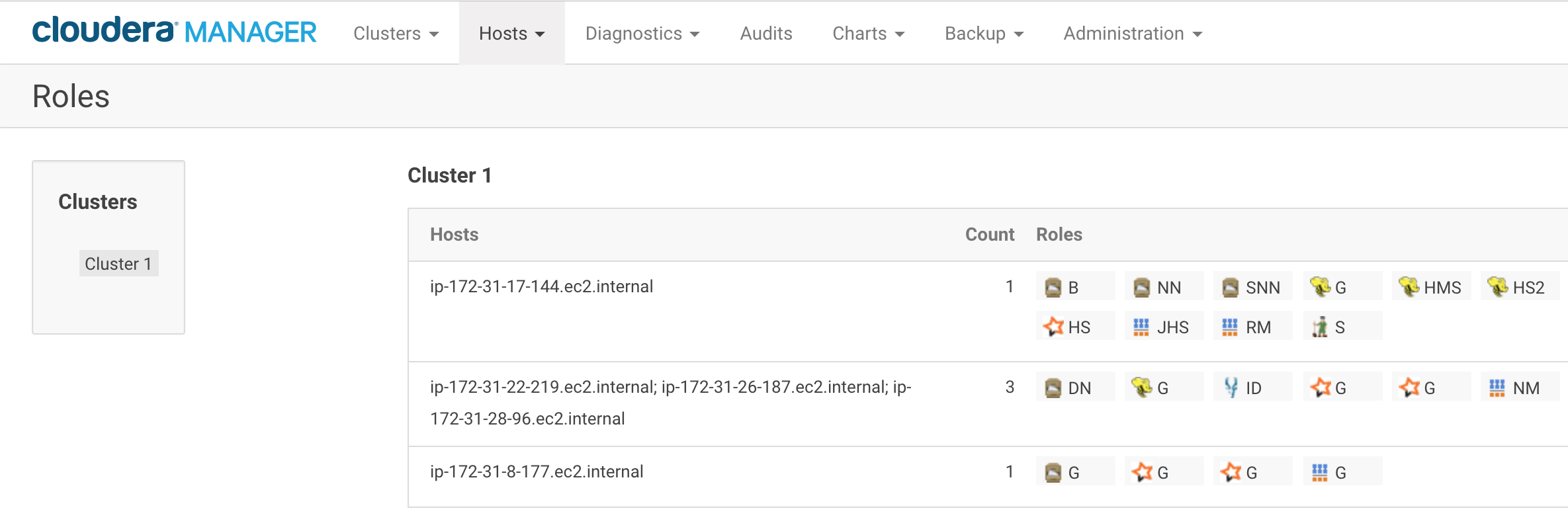
在您添加了所有必要的角色之后,RStudio Workbench节点的集群角色应该类似于下图。英格兰vs伊朗让球
步骤7:验证Hadoop集群和HDFS上是否存在用户#
重要的是,登录到RStudio Workbench的相同用户也存在于Hadoop集群中。英格兰vs伊朗让球这是因为RStudio/Jupyter会英格兰vs伊朗让球话将作为该用户运行,任何Spark上下文将继承该用户的YARN和HDFS权限。
信息
可以使用多种方法实现跨RStudio Workbench实例和H英格兰vs伊朗让球adoop集群同步用户。例如,可以通过LDAP/AD将两个系统配置为相同的身份提供程序。有关更多信息,您可以与Hadoop管理员进行更多讨论。
在HDFS中手动创建用户,可以使用如下命令(replace . txt)
<英格兰vs伊朗让球 rstudio >实际用户名):终端$ HDFS DFS -mkdir /user/<英格兰vs伊朗让球rstudio> $ HDFS DFS -chown rstudio:rstudio /user/rstudio/
步骤8:验证RStudio Workbench和Hadoop集群之间的网络连通性英格兰vs伊朗让球#
- 确保RStudio Workbe英格兰vs伊朗让球nch节点可以通过网络访问Cloudera CDH集群。在Amazon AWS中,我们建议允许Cloudera CDH安全组和RStudio Workbench安全组之间的所有通信。英格兰vs伊朗让球
使用RStu英格兰vs伊朗让球dio Workbench与Jupyter和PySpark#
现在RStudio英格兰vs伊朗让球 Workbench是Hadoop/Spark集群的一个成员,您可以安装和配置PySpark以在RStudio Workbench Jupyter会话上工作。
为用户
本节描述用户使用RStudio Workbench和Jupyter notebook通过PySpark连接到Spark英格兰vs伊朗让球集群的过程。
步骤1:在Python环境中安装PySpark#
在配置为Python内核的环境中安装PySpark,例如:
终端Sudo /opt/python/2.7.16/bin/pip install pyspark . shPython版本
PySpark不能在安装了不同小版本Python的情况下运行,请确保在RStudio Workbench和Spark集群中使用相同版本的Python。英格兰vs伊朗让球
步骤2:配置Spark的环境变量#
要为所有Jupyter会话配置Spark环境变量,请在
/etc/profile.d/它导出所需的配置变量,例如:文件:/etc/profile.d/spark.sh出口JAVA_HOME=/usr/lib/jvm/java - 1.8.0 openjdk 1.8.0.222.b10 - 1. - el7_7.x86_64 / jre出口HADOOP_CONF_DIR=/etc/hadoop/confJava版本和JAVA_HOME变量
确保您导出了一个
JAVA_HOME与PySpark编译所用的Java版本相匹配的变量。在本例中,我们使用的是Java Version 8。
步骤3:通过PySpark创建一个Spark会话#
现在,您已经准备好创建一个Spark会话并连接到Spark。
从RStudio 英格兰vs伊朗让球Workbench主页创建一个新的Jupyter Notebook或JupyterLab会话。
然后,进口
pyspark并在笔记本中运行以下Python代码,创建一个使用YARN的新的Spark会话:Python代码从pyspark进口SparkConf从pyspark进口SparkContext相依=SparkConf()相依.setMaster(“yarn-client”)相依.setAppName(“英格兰vs伊朗让球rstudio-pyspark”)sc=SparkContext(相依=相依)
步骤4:验证Spark应用程序在YARN中运行#
此时,您应该能够看到Spark应用程序正在YARN资源管理器中运行。
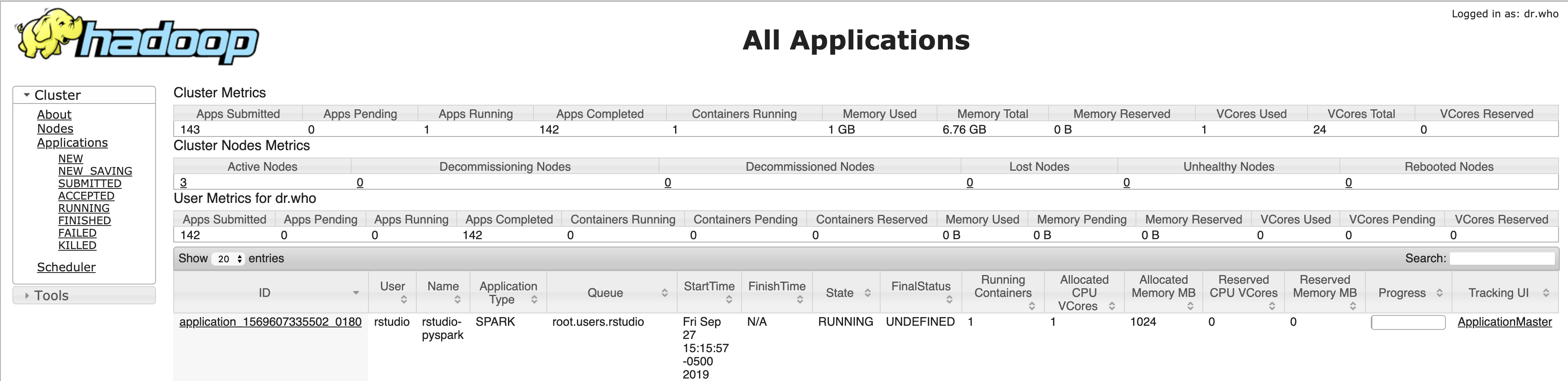
步骤5:运行一个示例计算#
您可以在笔记本中运行以下示例代码来验证Spark连接是否正常工作:
Python代码数据=(1,2,3.,4,5]distData=sc.并行化(数据)distData.的意思是()
步骤6:验证对HDFS的读写操作#
您可以在笔记本中运行以下示例代码来验证对HDFS的写入工作是否正常:
Python代码#保存文件到HDFS抽样=sc.并行化(范围(1,4)).地图(λx:(x,“一个”*x))抽样.saveAsSequenceFile(“saved_file”)您可以在笔记本中运行以下示例代码来验证从HDFS读取的操作是否正常:
Python代码#从HDFS读取相同的文件排序(sc.sequenceFile(“saved_file”).收集())